
Agent Evaluation Overview
| Rank | Agent | Model | Overall | API chaining |
Tool selection |
Multihop Reasoning |
MultiHop MultiSource Policy adherence |
|---|---|---|---|---|---|---|---|
| Loading… | |||||||
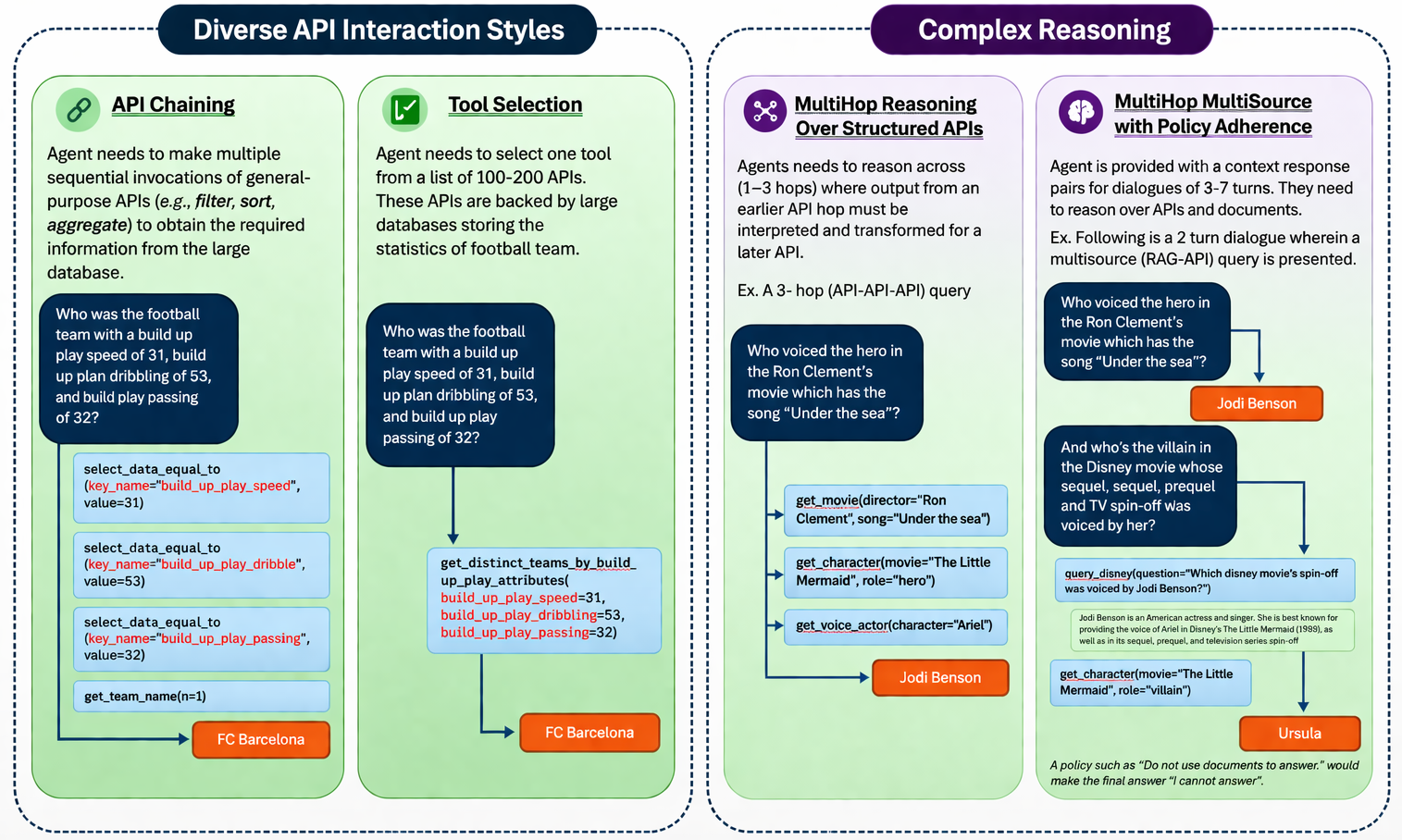
Four increasingly complex capabilities
We evaluates core agent capabilities—entity resolution, schema alignment, retrieval, tool selection, and policy adherence through four tasks
Submit to the live leaderboard
Ready to add your model to the public VAKRA leaderboard? Follow the submission flow below.
Run the benchmark
Evaluate your agent on the released VAKRA capabilities using the benchmark runner and evaluator present in the github repository.
Validate the output
The outputs are expected in a particular folder structure along with a metadata file created by the validator script. Run the validate_output.py script on the output folder. Provide the output of the validator script along with your submission.
Open the submission template
Use the leaderboard submission issue template to share your outputs, agent description, code or system link. Once reviewed, approved submissions will be added to the live leaderboard.
Submission resources
Everything needed to prepare a leaderboard entry is linked here.
Get started
Framework and scripts
Setup docs, baseline agents, and reproducible experiments.
Executable backends
Setup MCP based local APIs and retrieval stack.
Leaderboard and submissions
Please create a github issue using the Leaderboard Submission Template to submit for evaluation.
Benchmark paper
Link to the paper or blog page describing dataset construction coming soon.
Replay-based evaluation and scoring
The evaluator replays predicted tool trajectories against the live VAKRA MCP environment, injects fresh tool responses, and scores whether the final answer is correct and grounded in executed tool outputs.
Scoring pipeline
The current scorer evaluates the last turn for each dialogue. A waterfall judge is constructed using the following three judges :
- Policy check is only used for the multi-source with policy adherence capability. The output is programatically validated based on the policy per data sample.
- Exact-match tool-response check: looks for expected ground-truth tool responses in the predicted response set.
- Correctness check: if exact match fails, an LLM judge compares the predicted final answer to the ground-truth final answer.
- Groundedness check: acceptable answers are then checked against the executed tool outputs.
- Aggregation: turn scores are combined into a dialogue score using the default
meanpolicy.
Aggregate Benchmark Score
- Each of the four core capabilities are equally weighted to obtain the overall bechmark score.
- For multi-source with policy adherence capability multi-source queries have twice the weightage of queries requiring only APIs or only retrievers to answer.